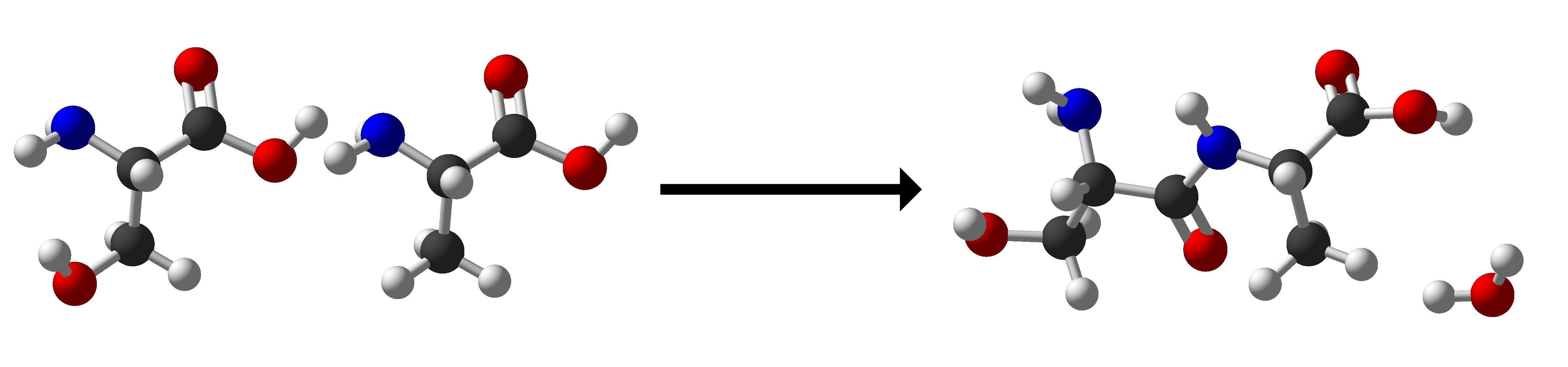
The primary sequence of a protein is the order that the amino acids it contains occur in. Proteins are chains of amino acids which are joined together into a single chain by peptide bonds (Figure 1). The order of the amino acids in the chain is a linear sequence, read along the length of these peptide bonds from the N-terminal (named for the nitrogen atom in an amine group) to the C-terminal (named for the carbon atom in a carboxylic acid group) end of the protein.
There are 20 amino acids (Table 1), which have a variety of chemical properties. They can be hydrophobic or hydrophilic, acidic, alkaline or neutral, have aromatic rings or be aliphatic, include atoms like sulfur. Proteins, as diverse molecules, have a wide range of properties, and a wide variety of amino acids that can be included to facilitate them.
| Amino Acid | 3 Letter Code | 1 Letter Code | Type | Structure | Formula |
|---|---|---|---|---|---|
| Alanine | Ala | A | Hydrophobic | 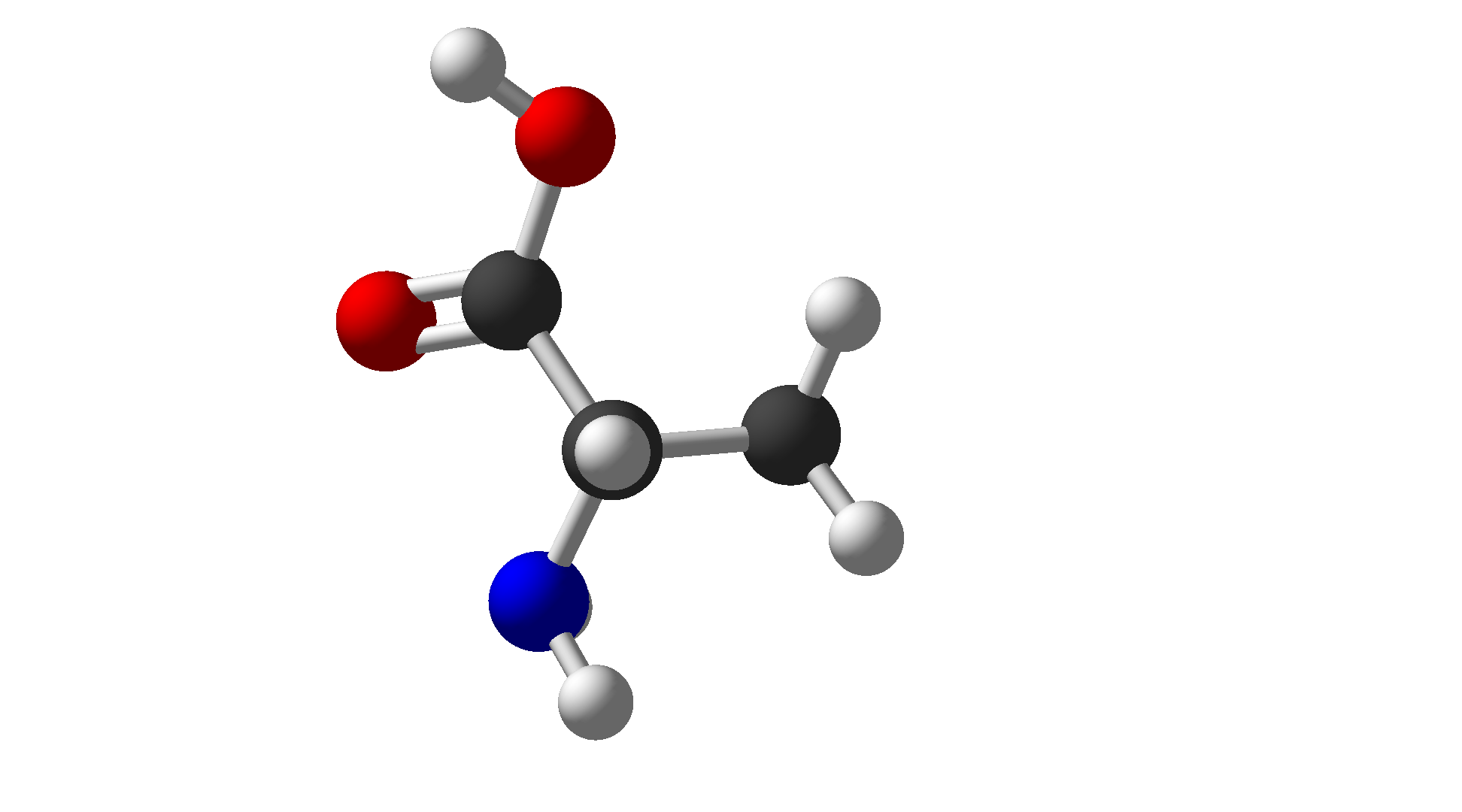 |
$\ce{C3H7NO2}$ |
| Cysteine | Cys | C | Special | 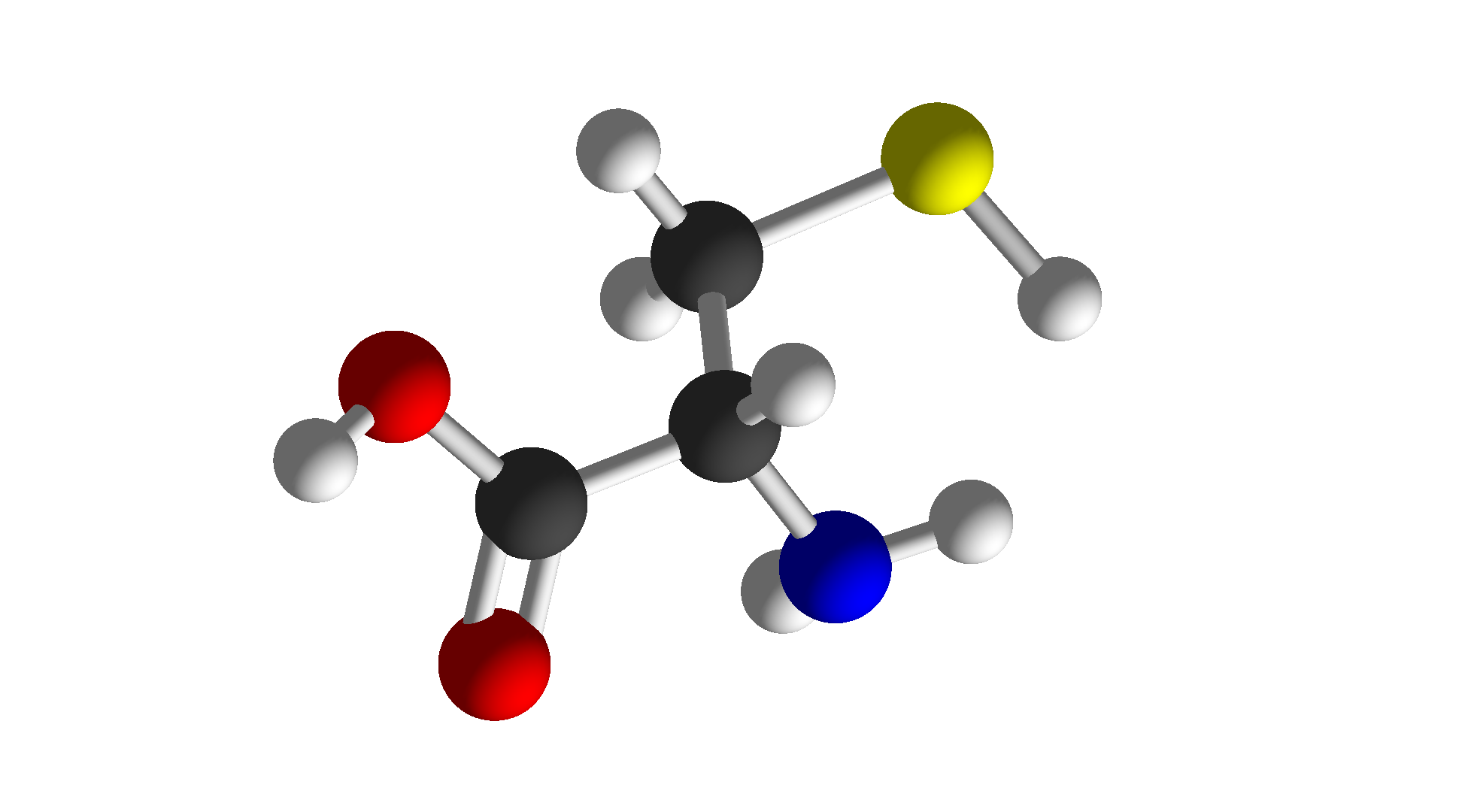 |
$\ce{C3H7NO2S}$ |
| Aspartic Acid | Asp | D | Acidic | 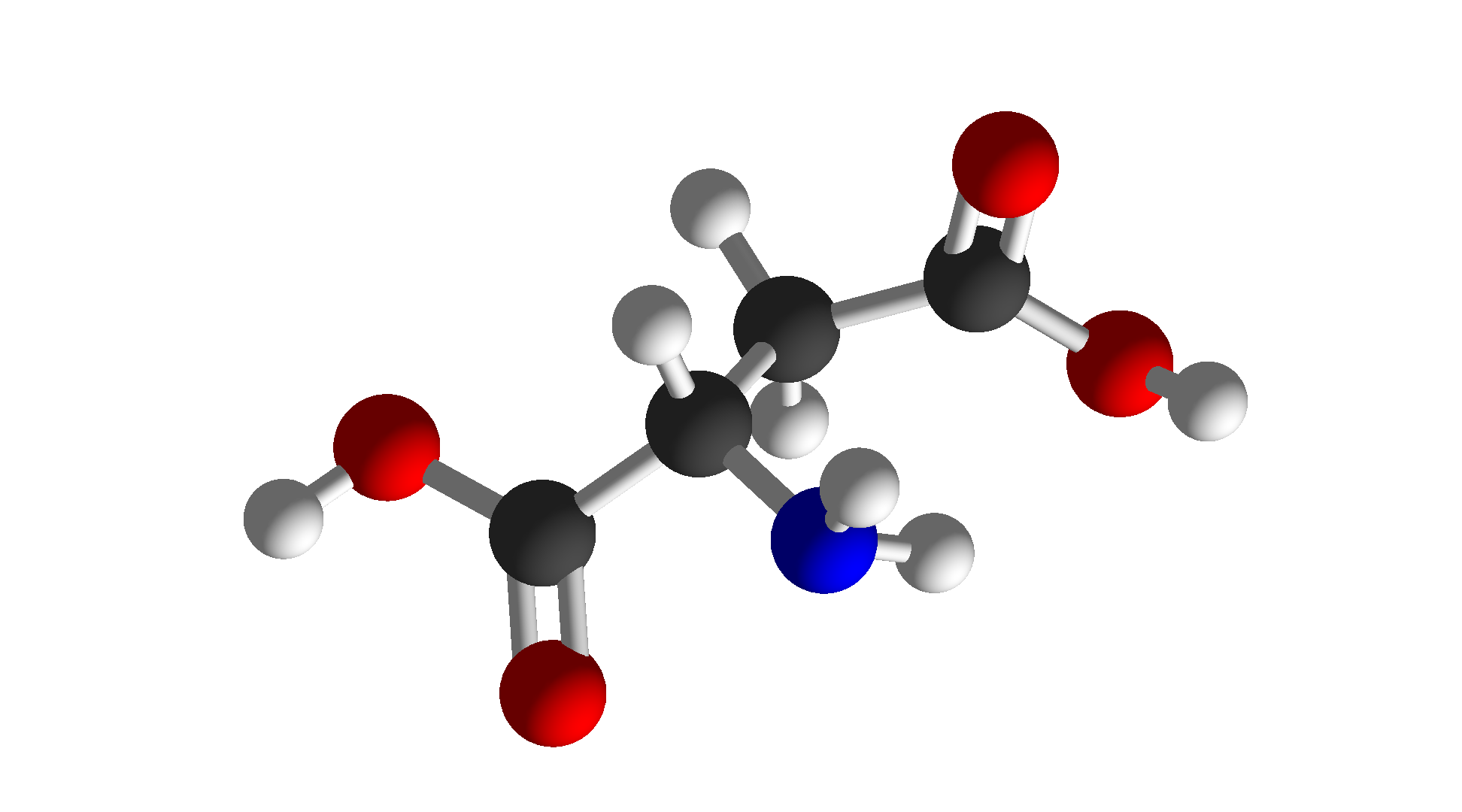 |
$\ce{C4H7NO4}$ |
| Glutamic Acid | Glu | E | Acidic |  |
$\ce{C5H9NO4}$ |
| Phenylalanine | Phe | F | Hydrophobic | 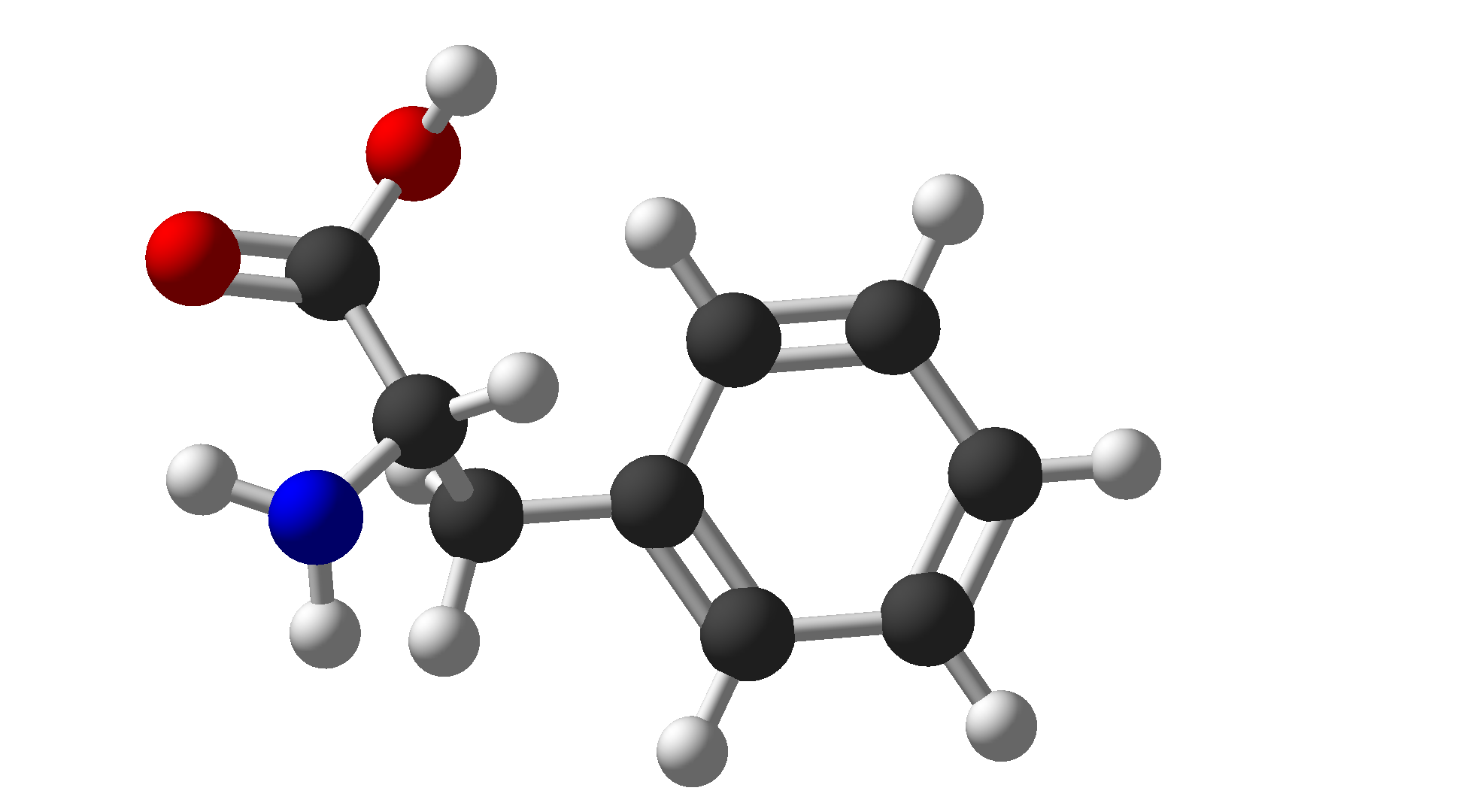 |
$\ce{C9H11NO2}$ |
| Glycine | Gly | G | Special | 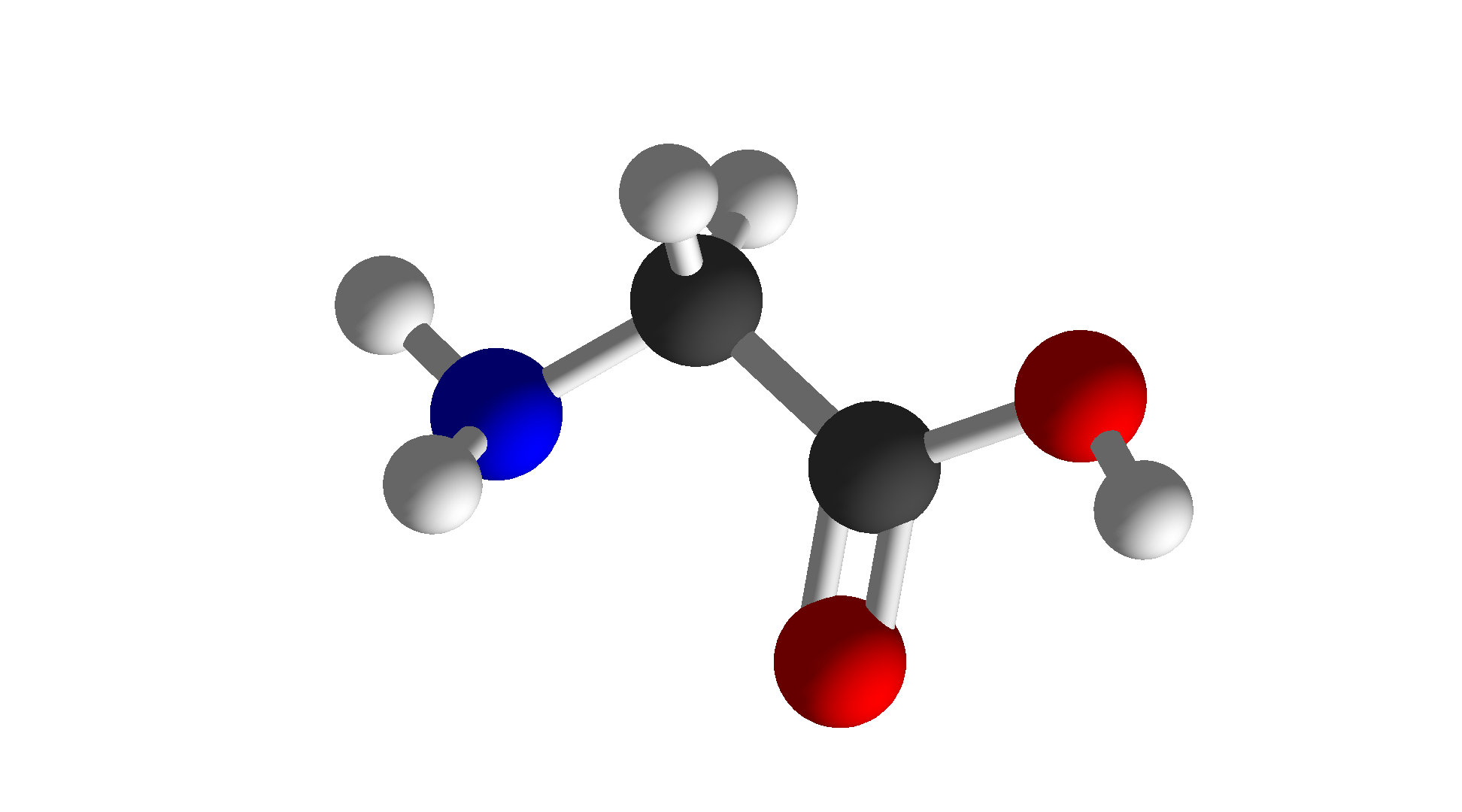 |
$\ce{C2H5NO2}$ |
| Histidine | His | H | Basic | 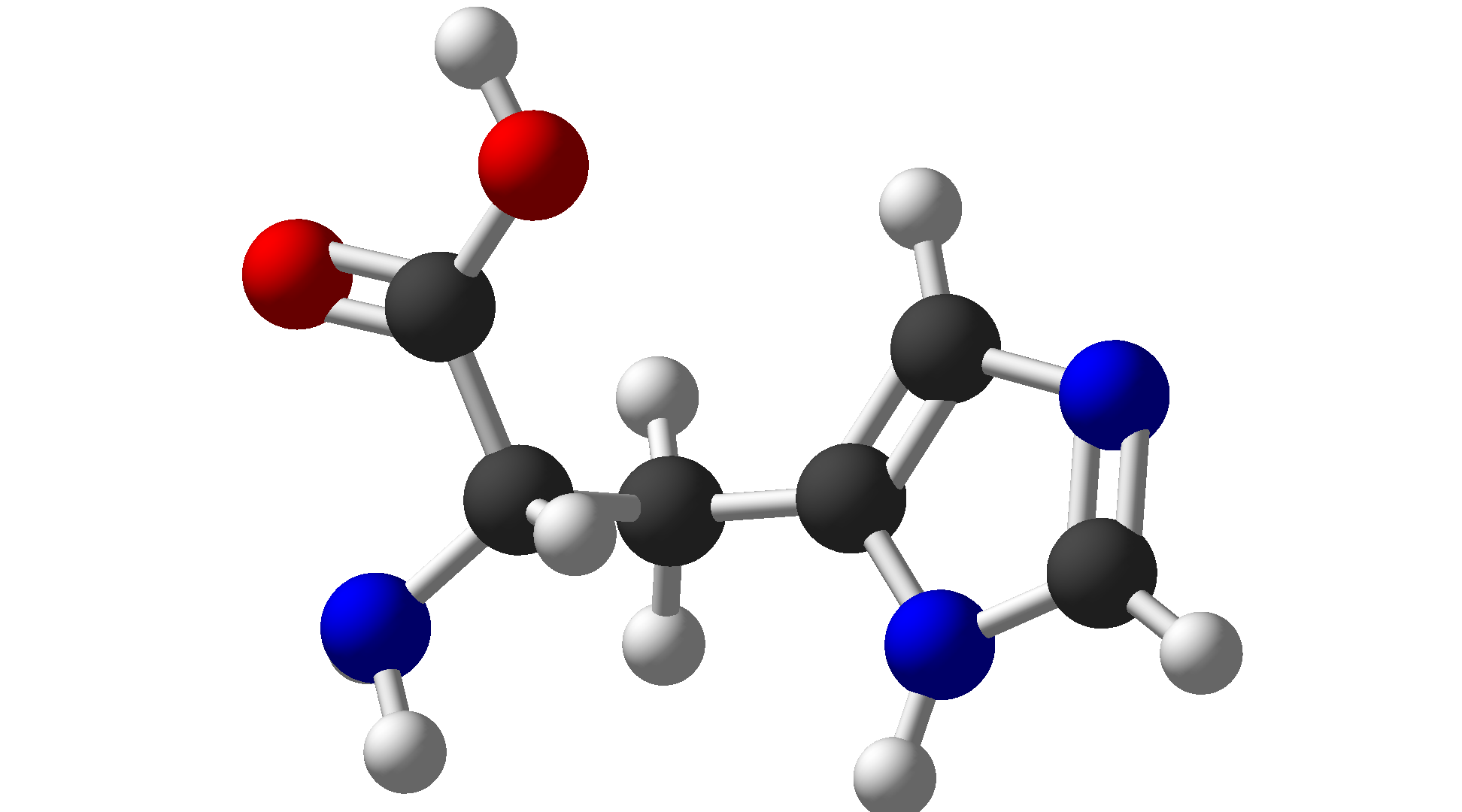 |
$\ce{C6H9N3O2}$ |
| Isoleucine | Ile | I | Hydrophobic | 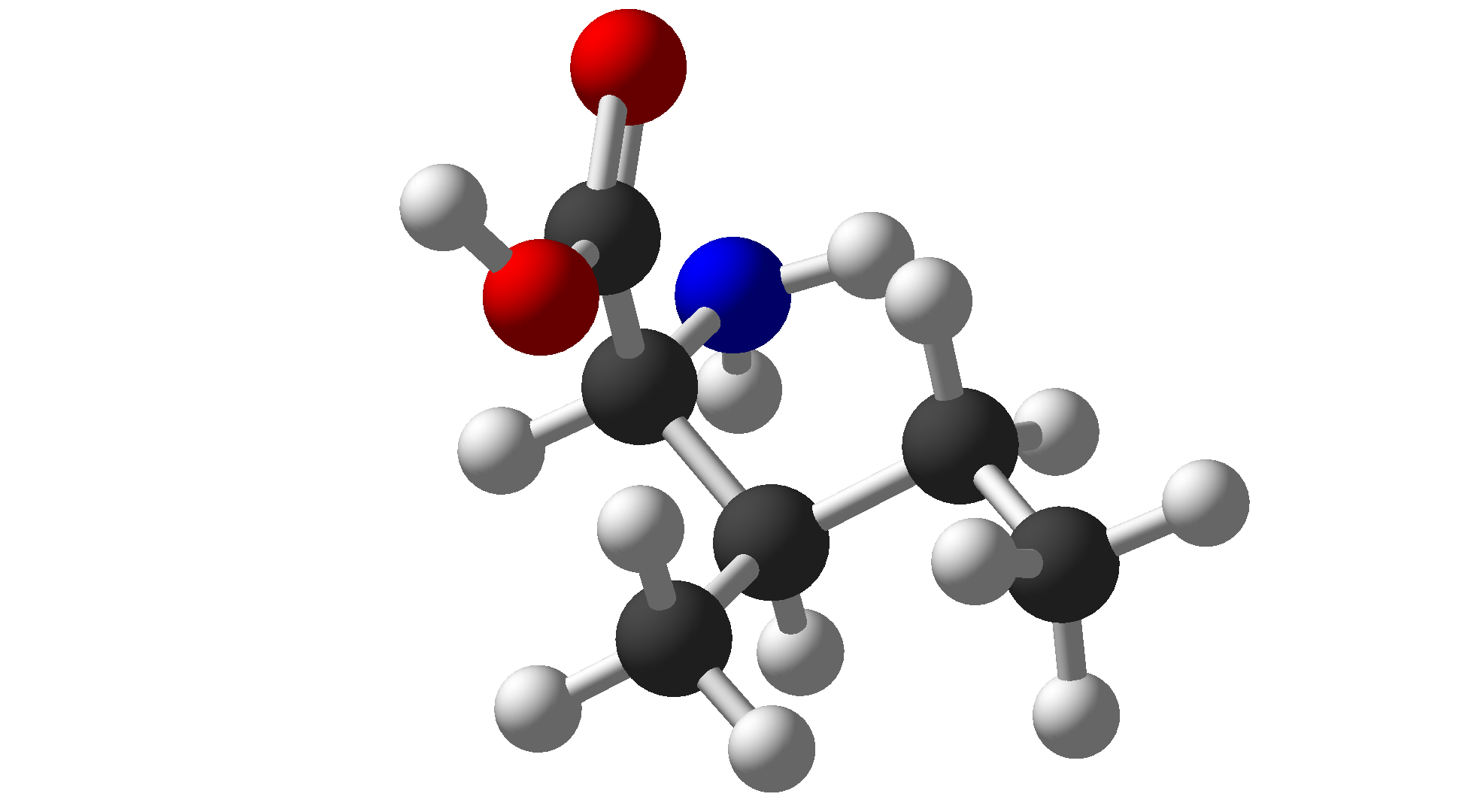 |
$\ce{C6H13NO2}$ |
| Lysine | Lys | K | Basic | 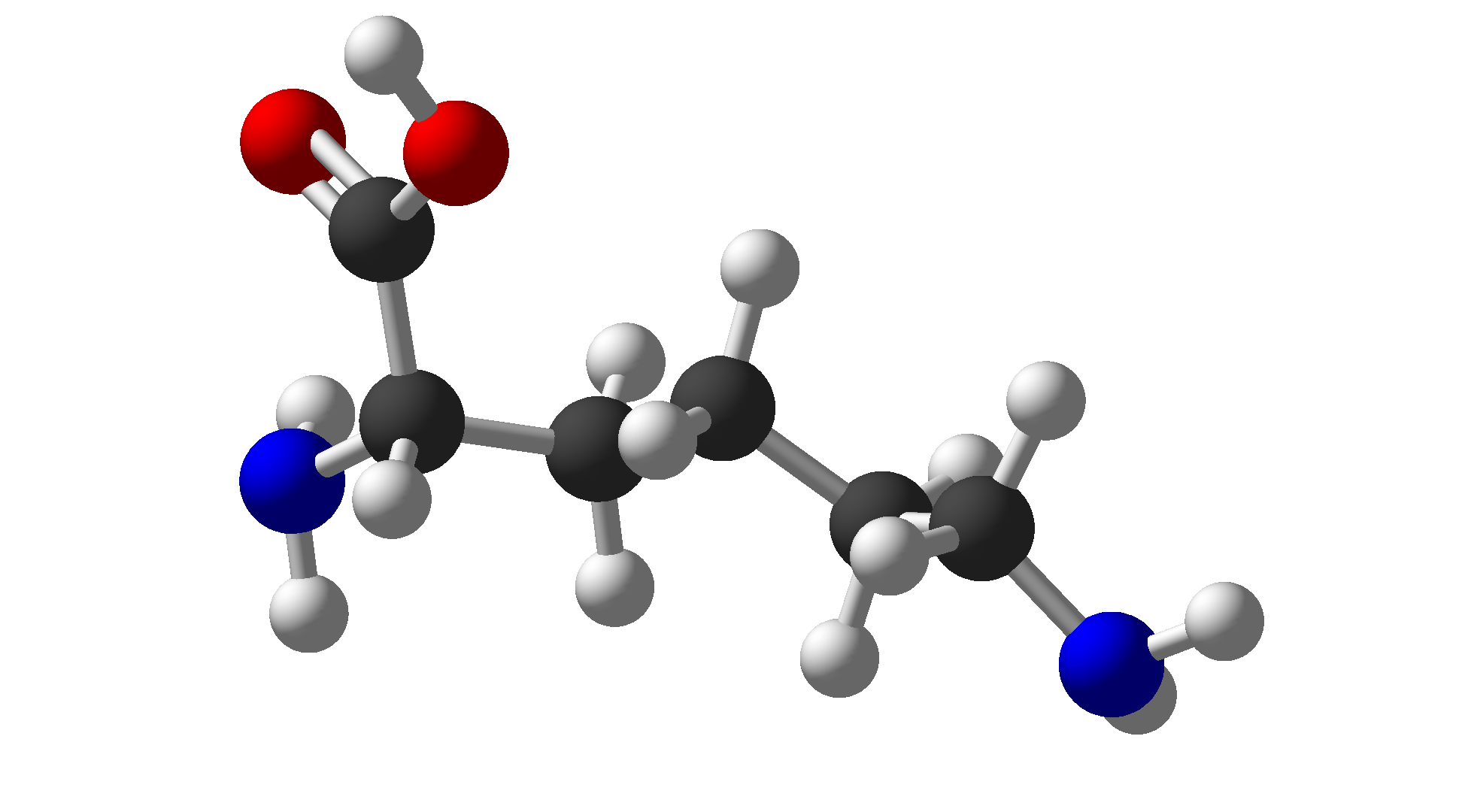 |
$\ce{C6H14N2O2}$ |
| Leucine | Leu | L | Hydrophobic | 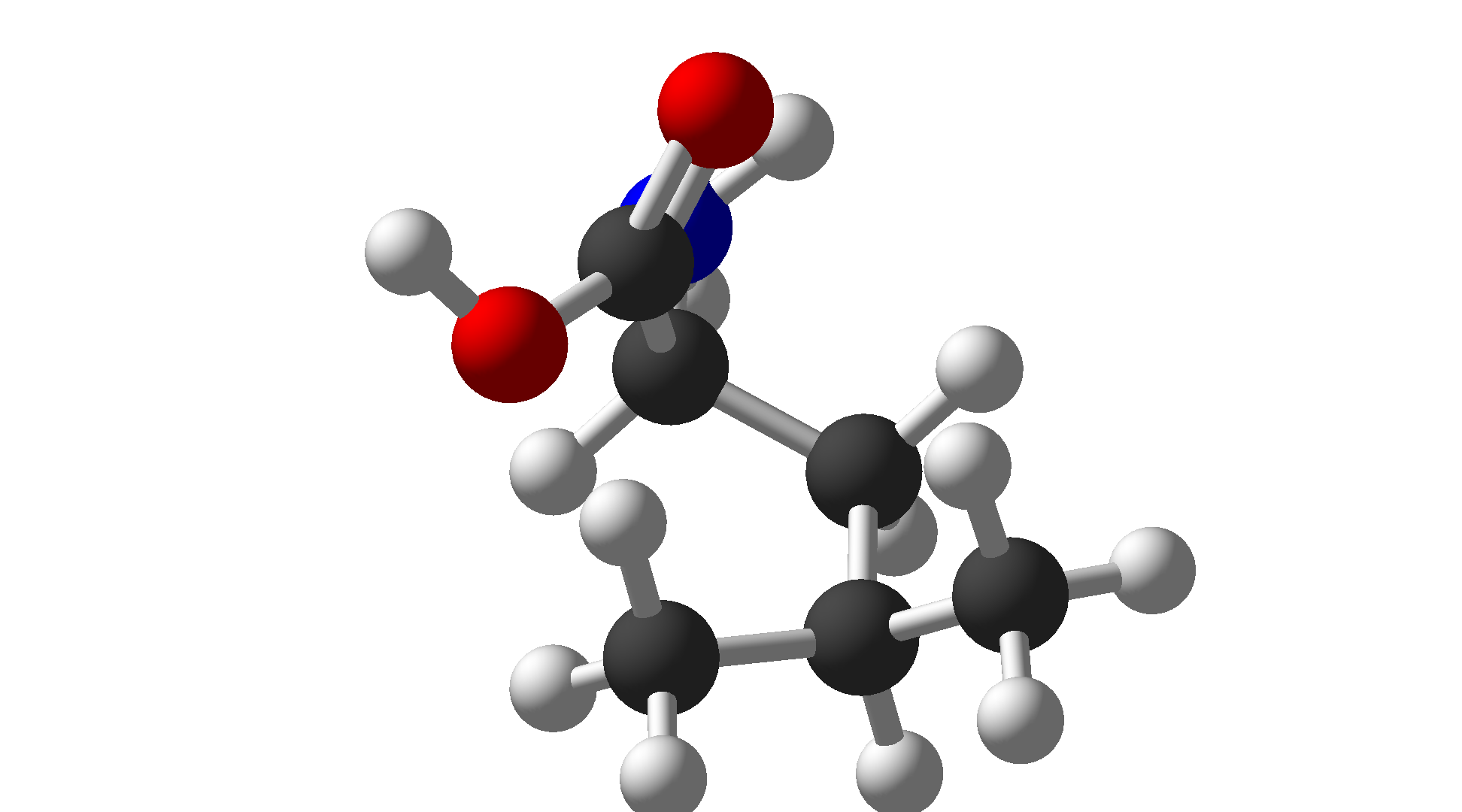 |
$\ce{C6H13NO2}$ |
| Methionine | Met | M | Hydrophobic | 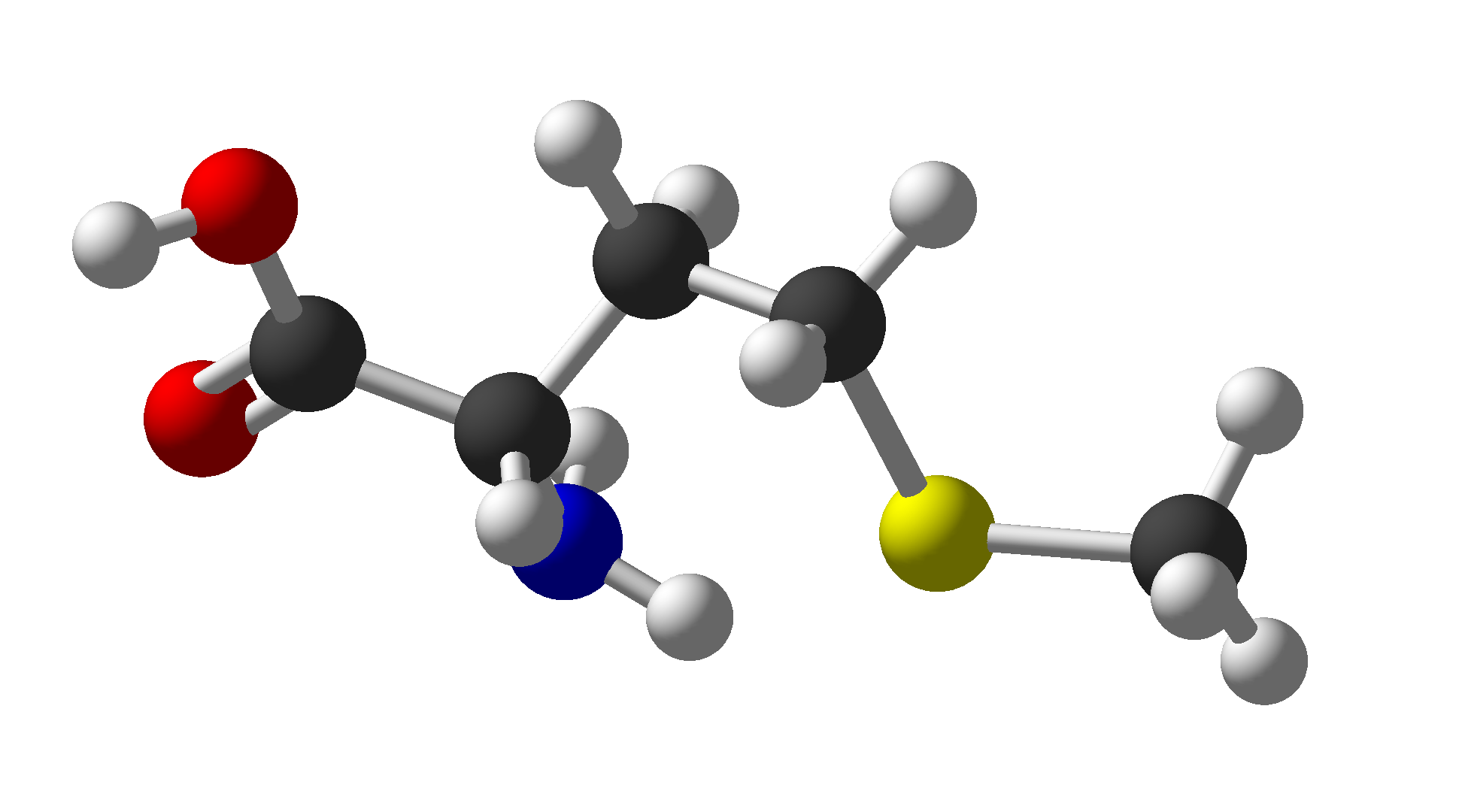 |
$\ce{C5H11NO2S}$ |
| Asparagine | Asn | N | Polar | 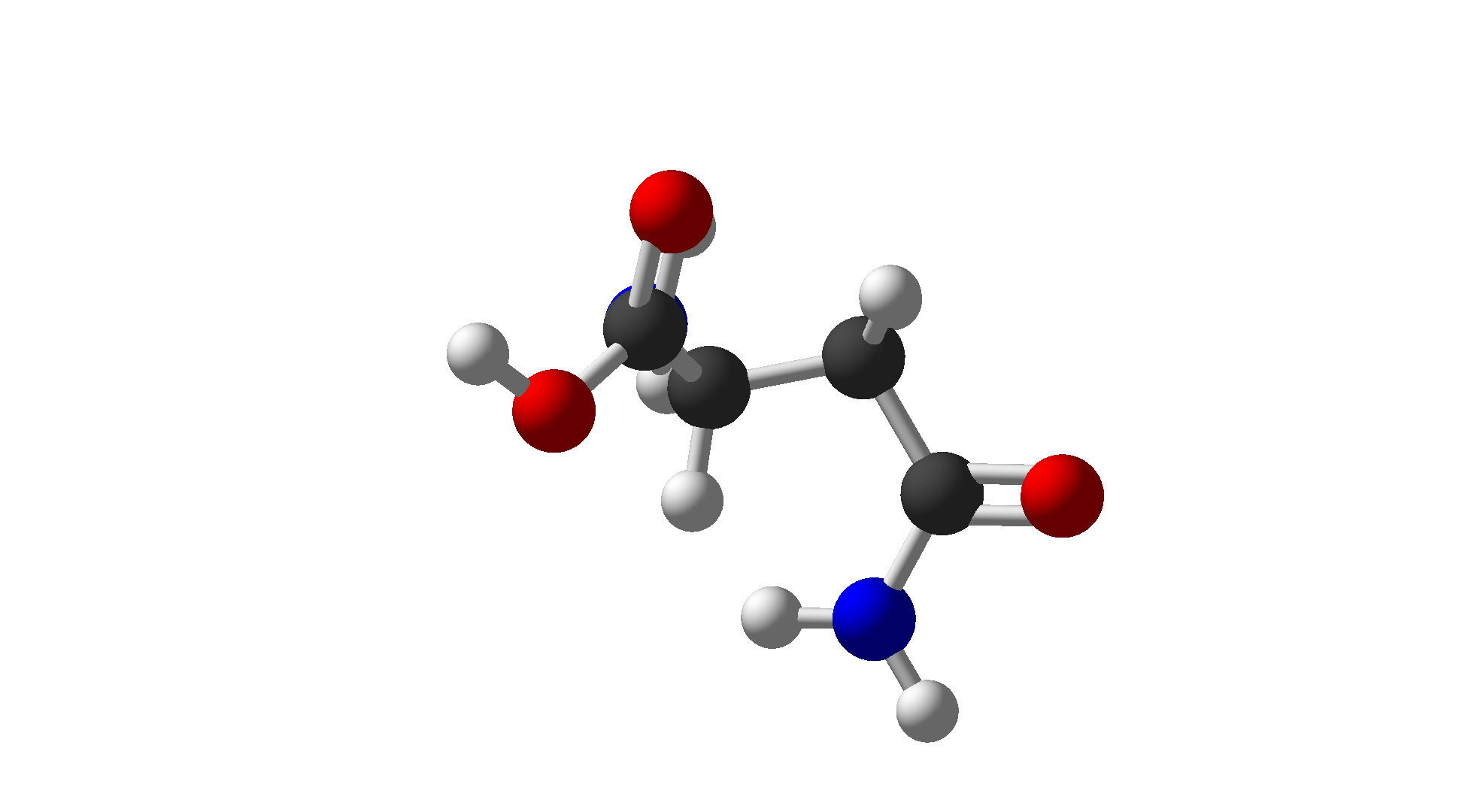 |
$\ce{C4H8N2O3}$ |
| Proline | Pro | P | Special | 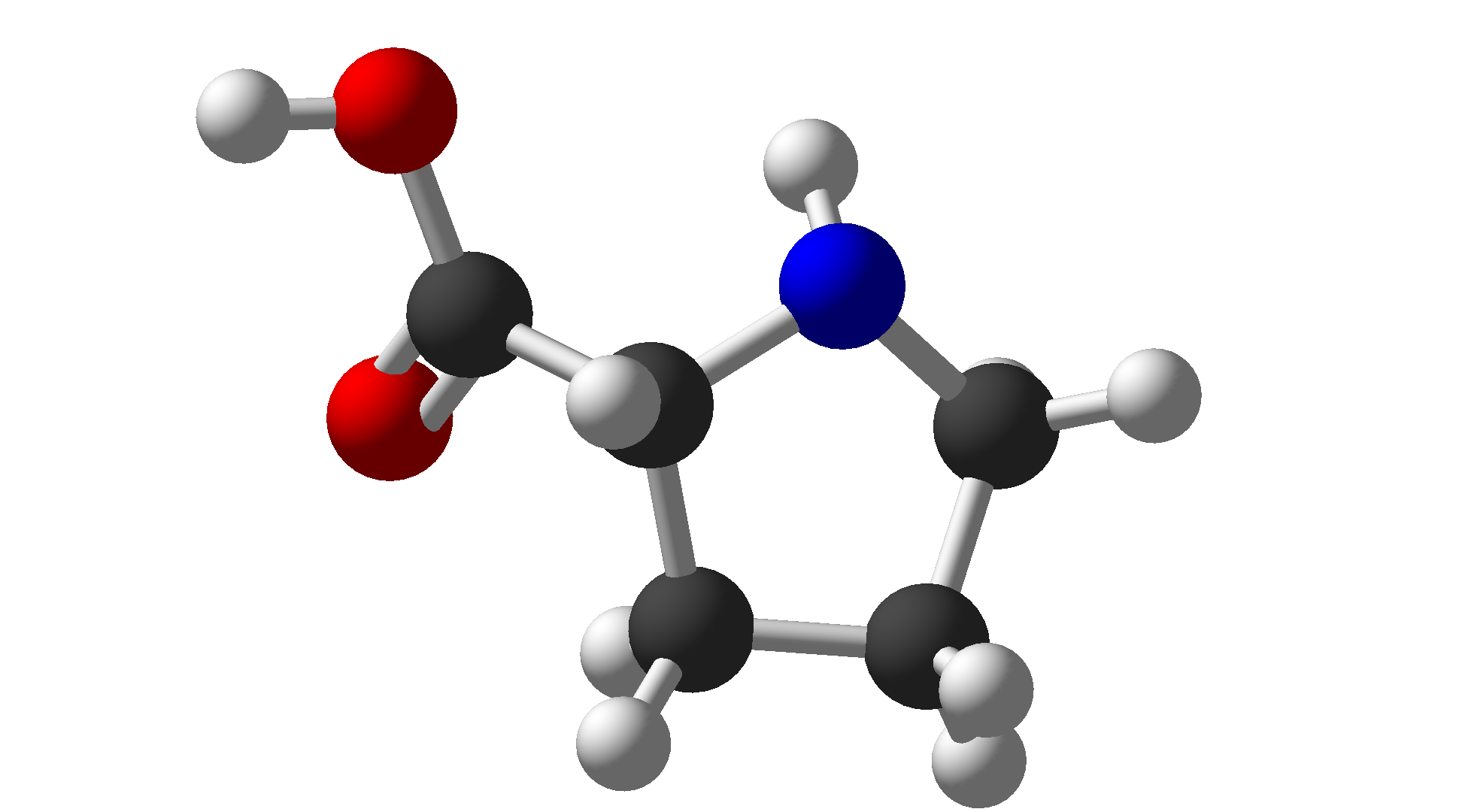 |
$\ce{C5H9NO2}$ |
| Glutamine | Gln | Q | Polar | 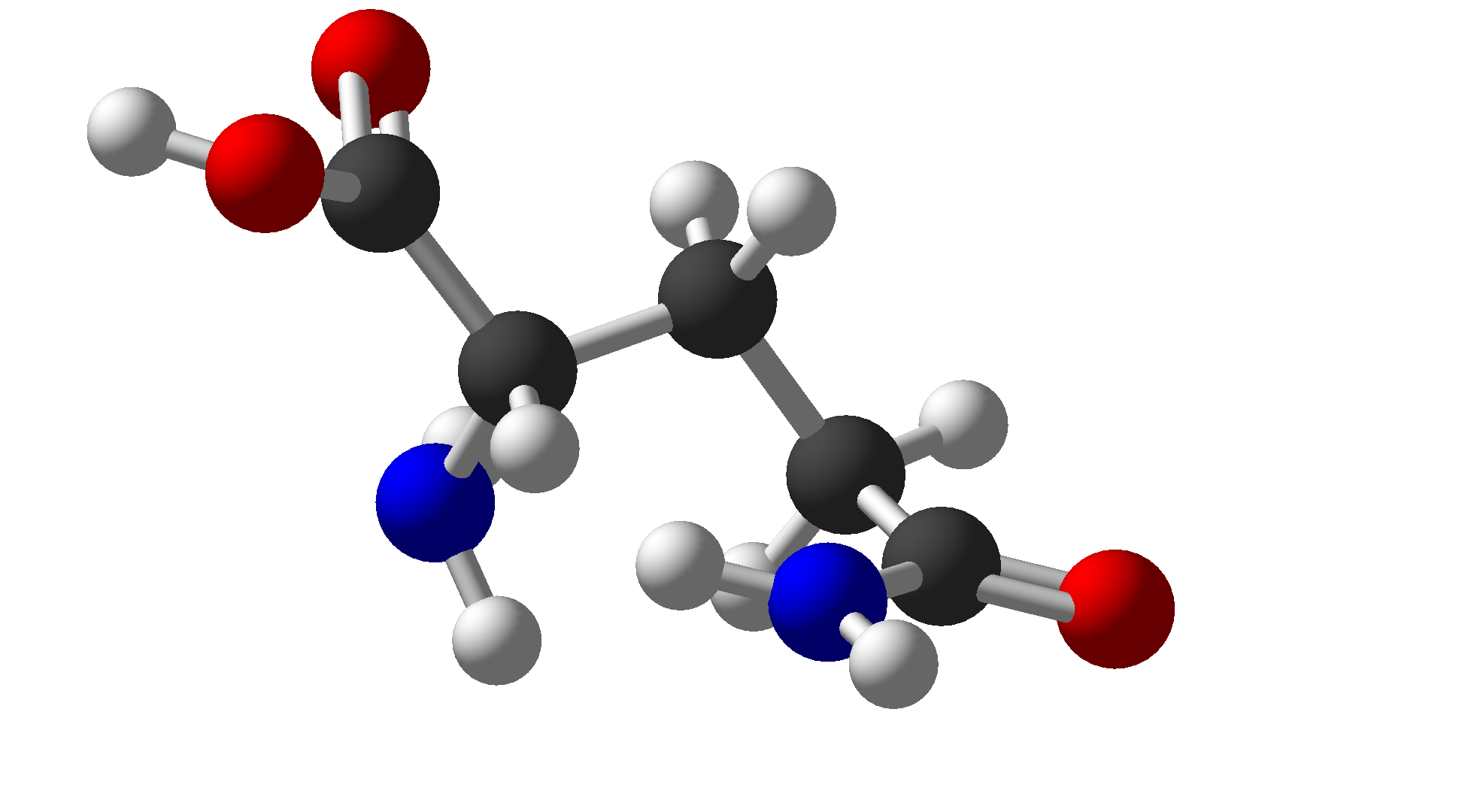 |
$\ce{C5H10N2O3}$ |
| Arginine | Arg | R | Basic | 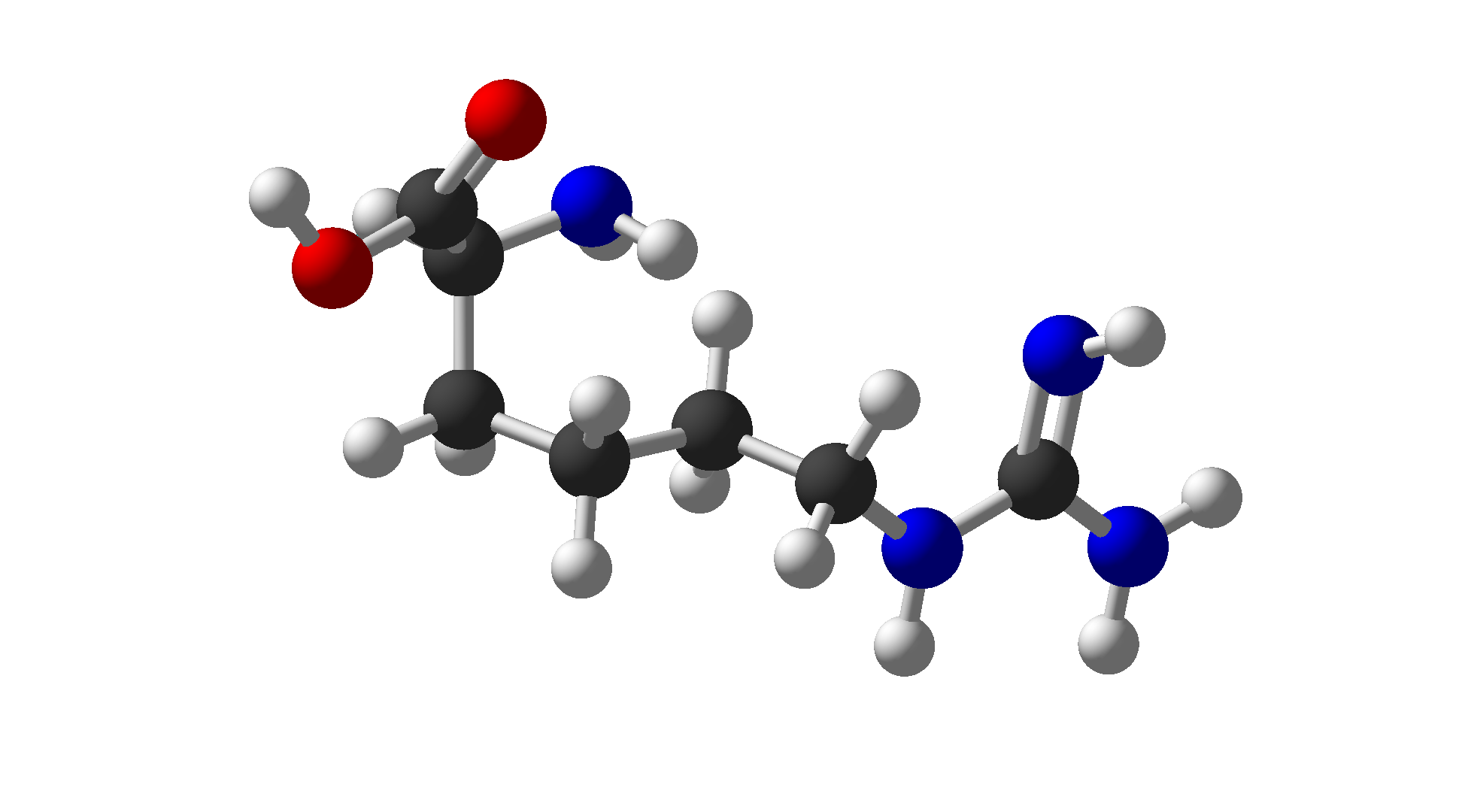 |
$\ce{C6H14N4O2}$ |
| Serine | Ser | S | Polar | 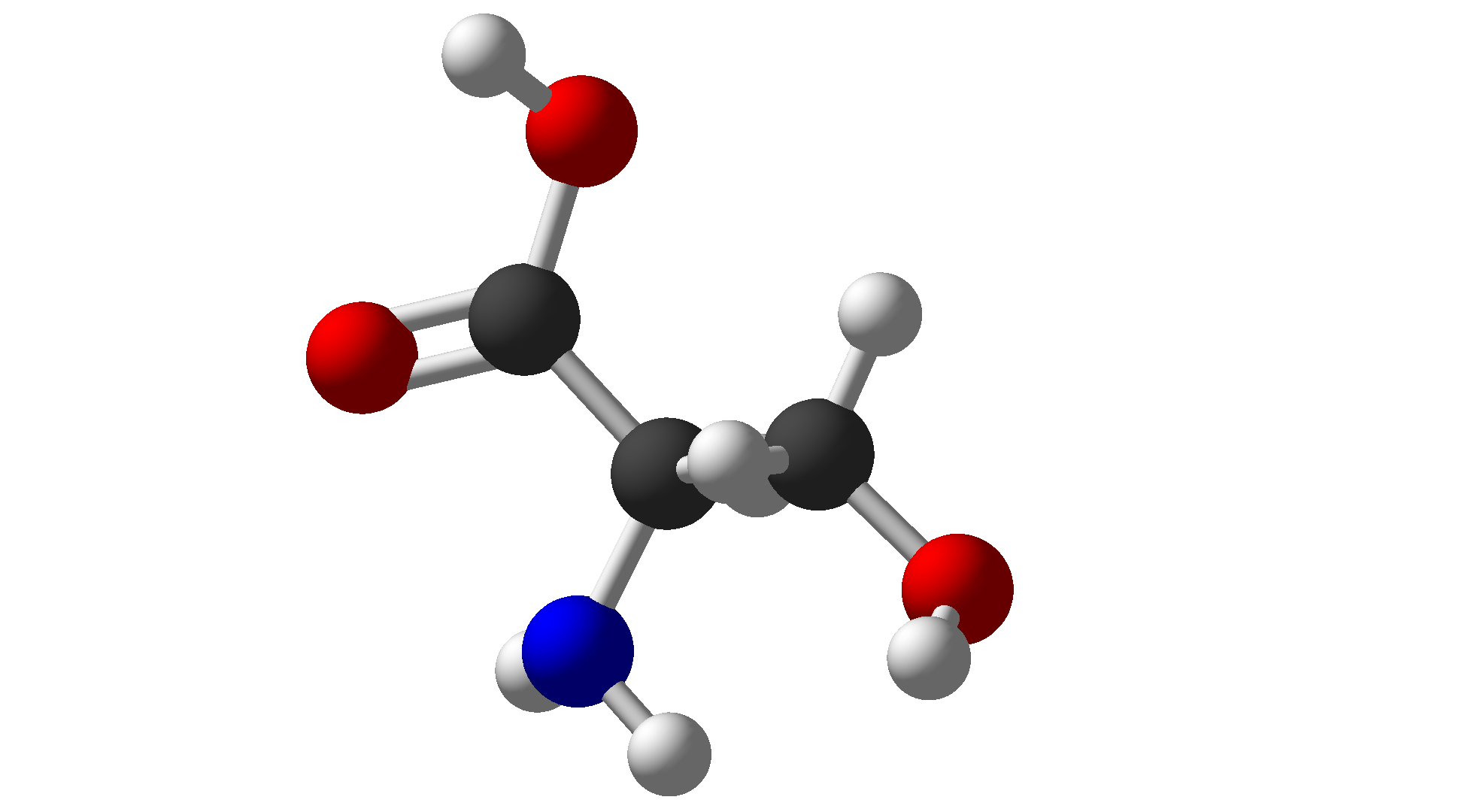 |
$\ce{C3H7NO3}$ |
| Threonine | Thr | T | Polar | 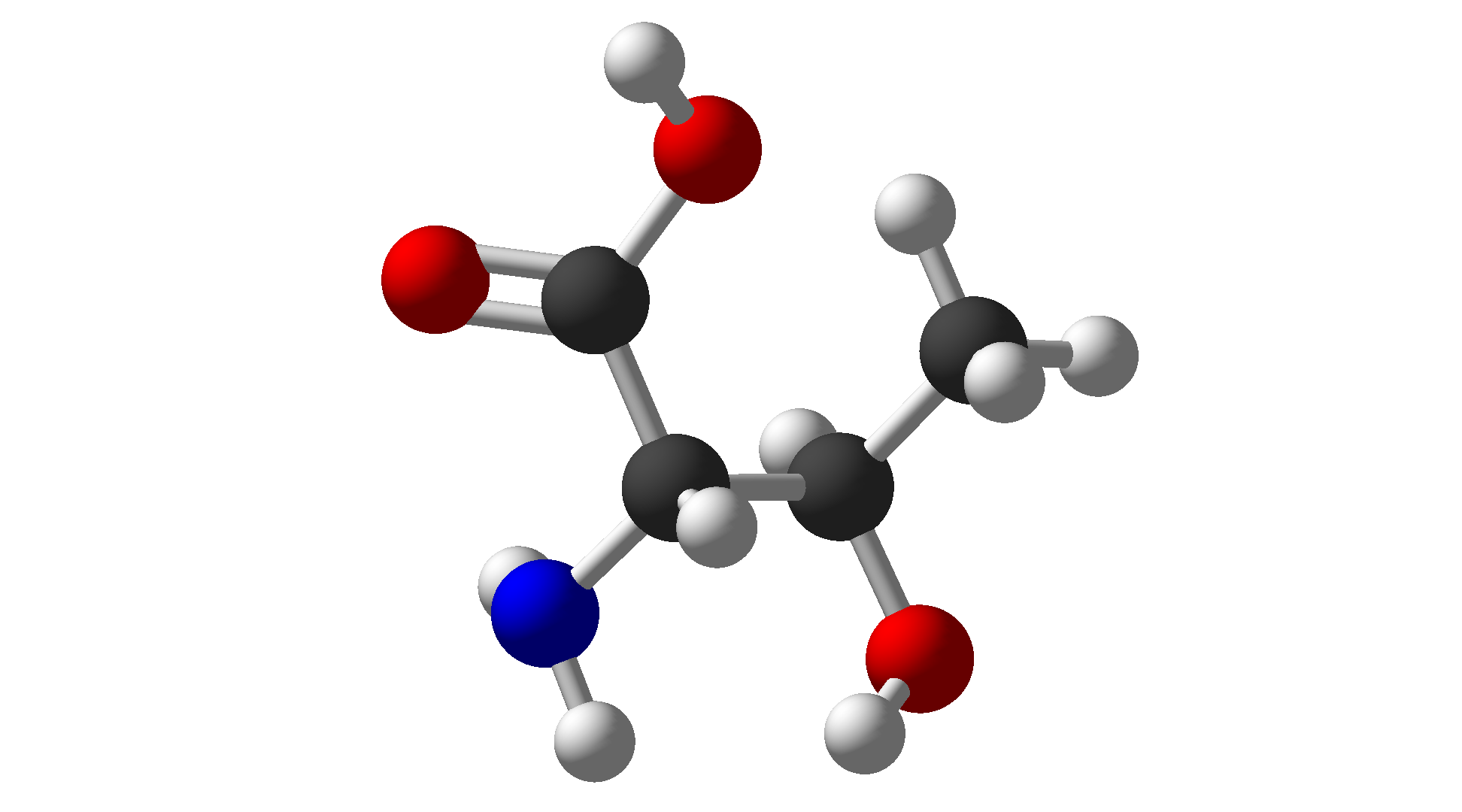 |
$\ce{C4H9NO3}$ |
| Valine | Val | V | Hydrophobic | 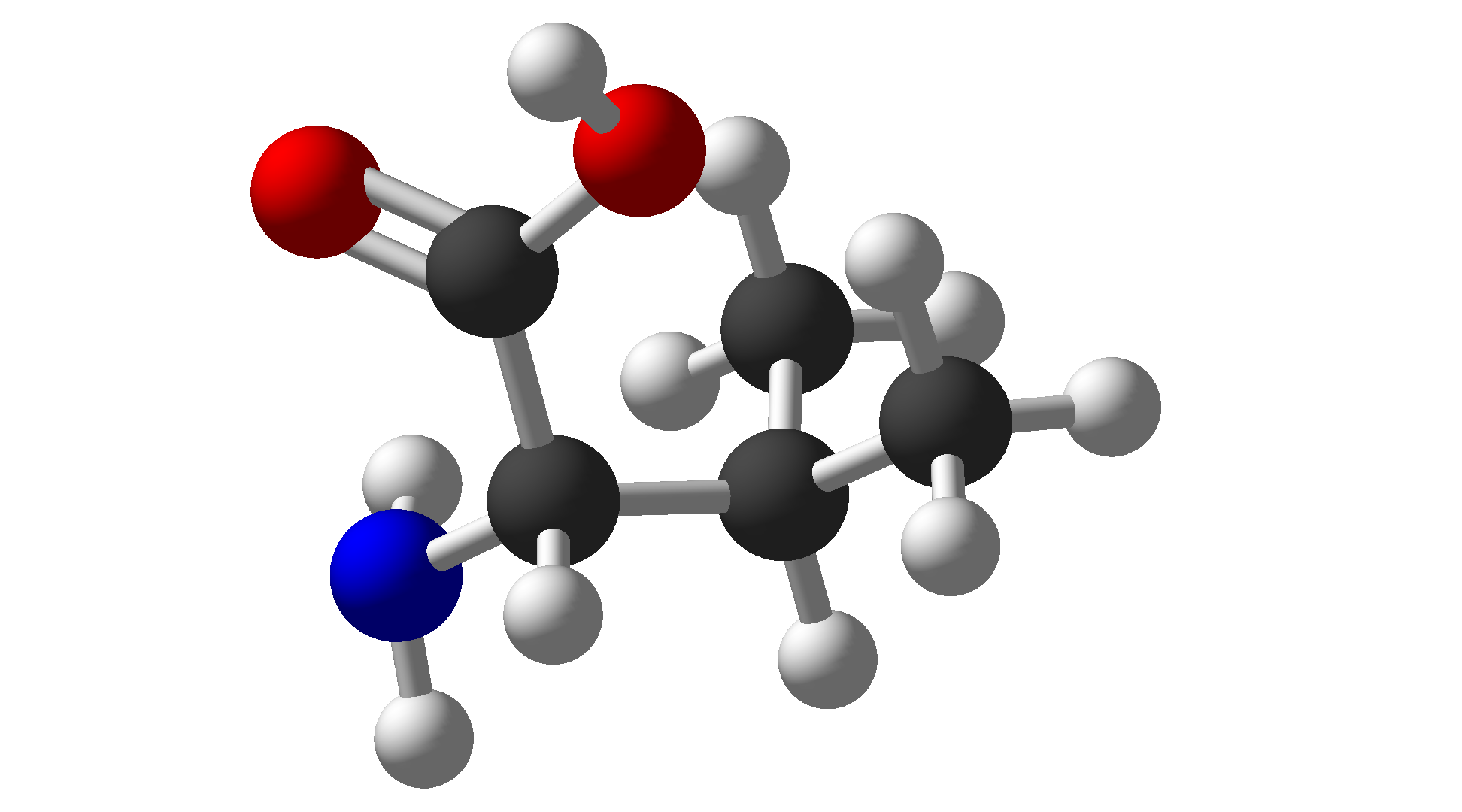 |
$\ce{C5H11NO2}$ |
| Tryptophan | Trp | W | Hydrophobic |  |
$\ce{C11H12N2O2}$ |
| Tyrosine | Tyr | Y | Hydrophobic | 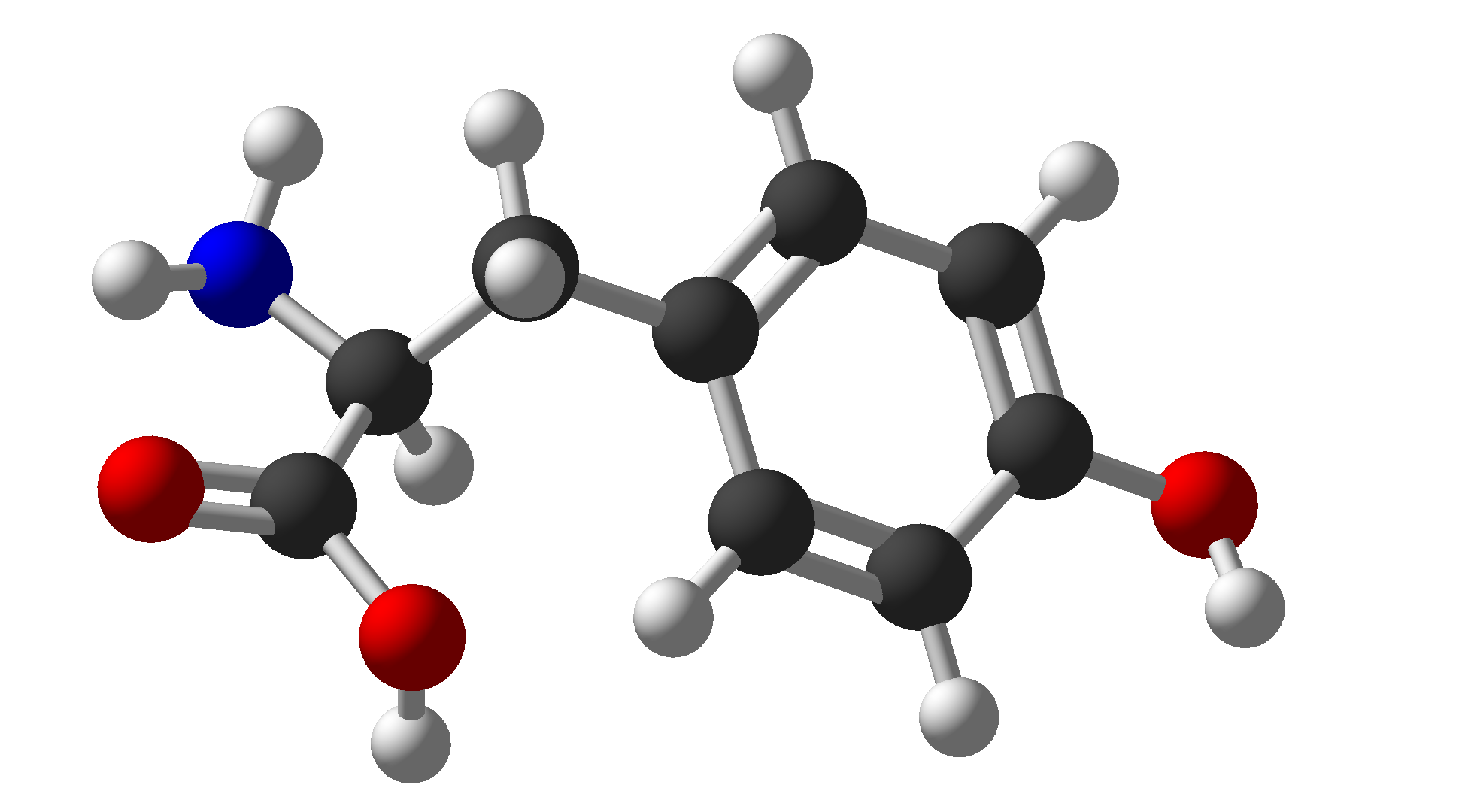 |
$\ce{C9H11NO3}$ |
The primary amino acid sequence can be represented as a linear sequence of letters, with each letter representing one amino acid. This has given rise to protein databases, notably the UniProtKB, where such sequences of proteins can be downloaded.
The protein sequence is inherently tied to the DNA sequence associated with it. DNA, transcribed into mRNA and translated into a primary protein sequence linking these three sequences. Each combination of 3 nucleotides (known as codons) encodes a single amino acid, so it is trivial for changes in the DNA sequences to predict changes to the protein primary sequence. It is also easy to store and analyze these sequences using computer algorithms, as they are strings.
The protein primary sequence begins the story of the structure and function of a protein. Next the protein folds into a secondary structure.